标题:Generative Adversarial Nets
作者:Ian Goodfellow, Jean Pouget-Abadie, etc.
发表:NIPS 2014
论文提出了一个利用对抗过程进行生成的模型,主要有两个部分组成:一个生成模型G来学习数据的分布,一个判别模型D来评估一个样本来自训练数据而不是D的概率。G的训练目标就是最大化D给出错误判断的概率。对于这个模型论文给出了一个形象的比喻,G就像制造假钞的人,而D是警察,D的目标是检验出哪些是“假钞”,哪些是“真钞”,G的目标则是制作出足够真实的“假钞”来骗过D。论文证明了对于可取任意函数的G和D,存在特殊的解使得G能够模拟出训练数据的分布并使D在任何取值上都等于 \(\frac{1}{2}\)。
对抗网络
为了学习数据 \(x\) 的概率分布 \(p_g\), 首先定义输入噪声的先验概率 \(p_z(z)\) ,然后通过用带参数 \(\theta_g\) 的多层感知机表示的可微分函数 \(G\) ,将噪声映射到数据空间 \(G(z;\theta_g)\) 。并且定义另一个多层感知机 \(D(x;\theta_d)\) ,它输出一个标量 \(D(x)\) 表示 \(x\) 来自数据而不是 \(p_g\) 生成的概率。训练过程中,让 \(D\) 最大化分配正确标签的概率,同时让 \(G\) 最小化 \(log(1-D(G(z)))\) 。即 \(D\) 和 \(G\) 在进行对目标函数 \(V(G,D)\) 的minimax game: \[ \min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] \]
对于该训练方法,论文给出以下图示解释: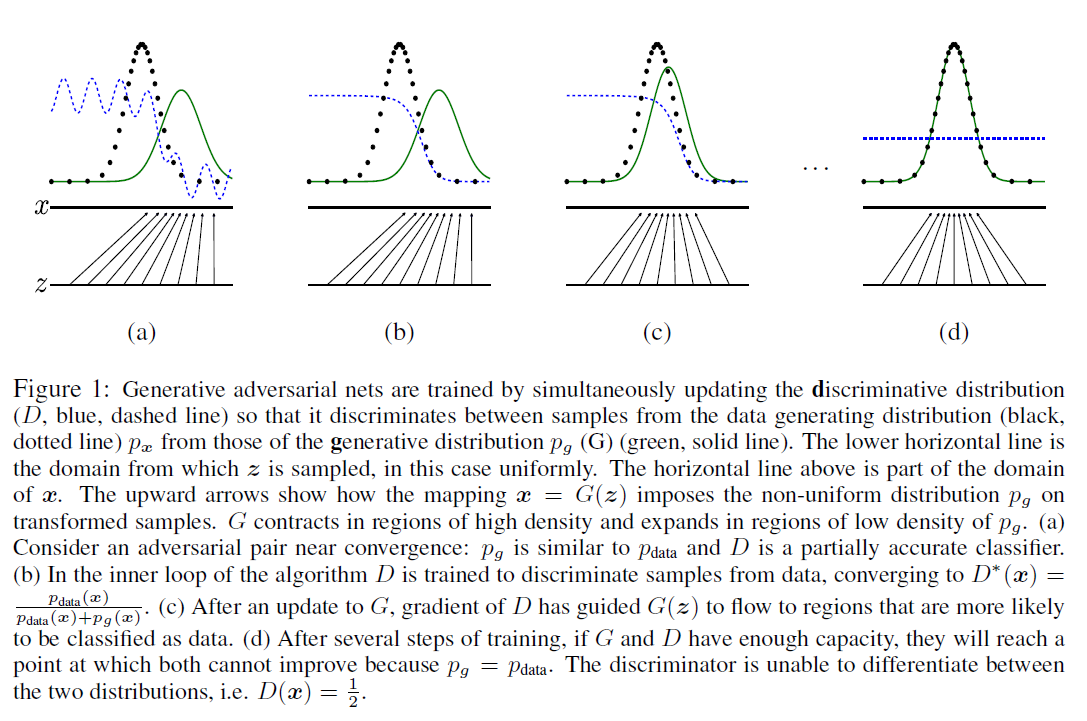
理论结果
生成器 \(G\) 对于输入噪声 \(\boldsymbol{z} \sim p_{\boldsymbol{z}}\) 隐式地定义了一个概率分布 \(G(z)\) 。因此如果给定足够的存储空间和训练时间,可以利用该方法获取数据分布 \(p_{\text {data }}\) 的很好模拟。其算法如下:

之后,论文通过理论推导,证明了:
1.对于固定的 \(G\),最优的判别器 \(D\) 为: \[ D_{G}^{*}(\boldsymbol{x})=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} \]
2.训练过程中,当且仅当 \(p_g = p_{data}\) 时,目标函数取得全局最小值 \(-log4\)。
3.如果 \(G\) 和 \(D\) 有足够的容量,在算法中的每一步,对给定的 \(G\) ,判别器 \(D\) 会达到它的最优解,并且 \(p_g\) 会不断更新收敛于 \(p_{data}\)
优缺点
优点: 不需要用到马尔科夫链,仅需反向传播获得梯度。学习过程中不需要用到推断(inference)。模型可以利用到多种形式的函数。
缺点:没有 \(p_g(x)\) 的显式表达式。 \(D\) 必须与 \(G\) 同步训练并同时取得比较好的结果。计算复杂度比较高。