标题:Generating Text via Adversarial Training
作者:Yizhe Zhang, Zhe Gan, Lawrence Carin
发表:NIPS 2016
论文使用LSTM作为生成器,CNN作为判别器来进行对抗训练生成文本,在训练生成器时,使用匹配特征分布的方法。另外,论文还使用了多种预训练的方法并解决了离散变量的问题。
文本生成一个简单的方法就是通过基于 RNN 的 encoder-decoder 学习表示句子的隐藏空间,然后通过解码隐藏空间的随机样本来生成句子。但是用autoencoder将句子映射到潜在向量空间时,映射往往只会覆盖很小的结构性的区域,所以如果选择嵌入空间的任意向量的话,解码很可能得到无意义的句子。另外一个不足是因为RNN的结构很可能导致错误的累计,就致使句子的前半部分较合理但后半部分偏差就比较大。而用GAN模型就能很好解决以上问题。
TextGAN
给定语料库 \(S = \{s_1,···,s_n\}\),其中 \(n\) 是句子的总数。令 \(w^t\) 表示句子 \(s\) 中的第 \(t\) 个词,每个词 \(w^t\) 使用 \(k\) 维的词向量 \(\mathbf{x}_t = \mathbf{W}_e[w^t]\) 嵌入表示,其中 \(\mathbf{W}_e \in \mathbb{R}^{k \times V}\) 是需要学习的词嵌入矩阵,\(V\) 是词典大小,符号 \([v]\) 表示矩阵的第 \(v\) 列。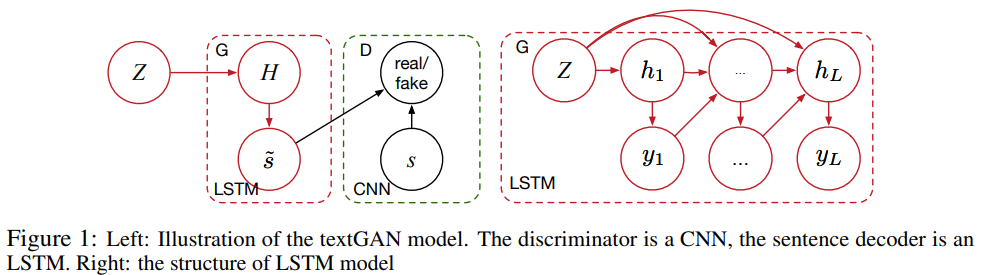
CNN判别器
CNN架构由卷积层和最大池化操作组成。一个长度为 \(T\) 的句子可以通过连接词嵌入向量作为每一列,表示为矩阵 \(\mathbf{X} \in \mathbb{R}^{T-h+1}\),即 \(\mathbf{X}\) 的第 \(t\) 列为 \(x_t\)。
卷积操作使用卷积核 \(\mathbf{W}_c \in \mathbb{R}^{k \times h}\),应用到相邻 \(h\) 个词汇产生特征。据此可以产生feature map \(\boldsymbol{c}=f\left(\mathbf{X} * \mathbf{W}_{c}+\boldsymbol{b}\right) \in \mathbb{R}^{T-h+1}\),其中 \(f(·)\) 是非线性激活函数,\(\boldsymbol{b} \in \mathbb{R}^{T-h+1}\) 是偏置向量。之后对feature map做max-over-time池化操作,即 \(\hat{c} = max\{\boldsymbol{c}\}\),该操作提取出重要信息且保证提取特征与输入句子长度无关。
在模型中会使用不同窗口大小的多个卷积核,在提取出来的向量特征层上会使用一个softmax层来将输入的句子映射到输出 \(D(\mathbf{X}) \in [0,1]\),表示 \(\mathbf{X}\) 属于真实数据分布的概率。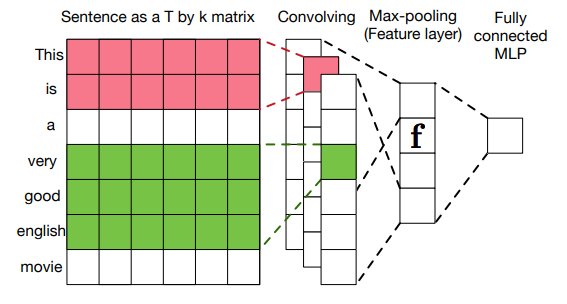
LSTM生成器
LSTM解码器由于将特征向量 \(z\) 转化成生成语句 \(\tilde{s}\)。给定特征向量 \(z\),生成长度为 \(T\) 的句子 \(\tilde{s}\) 的概率为: \[ p(\tilde{s} \mid \boldsymbol{z})=p\left(w^{1} \mid \boldsymbol{z}\right) \prod_{t=2}^{T} p\left(w^{t} \mid w^{<t}, \boldsymbol{z}\right) \]
特别的,\(p\left(w^{1} \mid \boldsymbol{z}\right) = \operatorname{argmax}(\mathbf{V}h_1)\),其中 \(h_1 = \tanh(\mathbf{C}\boldsymbol{z})\),\(\mathbf{V}\) 是一个用来计算词分布的权重矩阵。LSTM第 \(t\) 步的输入 \(\boldsymbol{y}_{t-1}\)是最大化 \(w^{t-1}\) 的上一个单词的嵌入向量: \[\boldsymbol{y}_{t-1} = \mathbf{W}_e[w^{t-1}] \tag{1}\] 则生成的句子 \(s=\left[\operatorname{argmax}\left(w^{1}\right), \cdots, \operatorname{argmax}\left(w^{L}\right)\right]\)。
训练技术
训练目标 不使用原始GAN模型目标函数,而是采用类似于特征匹配的方法,分两步进行迭代优化: \[ \text { minimizing: } L_{D}=-\mathbb{E}_{s \sim \mathcal{S}} \log D(s)-\mathbb{E}_{z \sim p_{z}(z)} \log [1-D(G(z))] \]
\[ \text { minimizing: } L_{G}=\operatorname{tr}\left(\boldsymbol{\Sigma}_{s}^{-1} \boldsymbol{\Sigma}_{r}+\boldsymbol{\Sigma}_{r}^{-1} \boldsymbol{\Sigma}_{s}\right)+\left(\boldsymbol{\mu}_{s}-\boldsymbol{\mu}_{r}\right)^{T}\left(\boldsymbol{\Sigma}_{s}^{-1}+\boldsymbol{\Sigma}_{r}^{-1}\right)\left(\boldsymbol{\mu}_{s}-\boldsymbol{\mu}_{r}\right) \]
其中 \(\boldsymbol{\Sigma}_{s}\),\(\boldsymbol{\Sigma}_{r}\)分别表示合成的和真实的句子特征向量 \(\boldsymbol{f}_{s}\),\(\boldsymbol{f}_{r}\) 的协方差矩阵,\(\boldsymbol{\mu}_{s}\),\(\boldsymbol{\mu}_{r}\) 表示 \(\boldsymbol{f}_{s}\),\(\boldsymbol{f}_{r}\) 的平均向量,他们都是从批样本中经验性地估计得来。损失函数 \(L_G\) 实际上是两个多变量高斯分布 \(\mathcal{N}(\boldsymbol{\mu}_{r},\boldsymbol{\Sigma}_{r})\) 和 \(\mathcal{N}(\boldsymbol{\mu}_{s},\boldsymbol{\Sigma}_{s})\) 的 JS 散度。
离散近似 训练的生成器 \(G\) 中包含离散变量,无法直接使用梯度。基于得分函数的方法,例如 REINFORCE 算法,通过蒙特卡洛估计获得无偏的梯度估计。但是梯度估计的方差会比较大。在这里使用一个 soft-argmax 函数进行估计: \[ \boldsymbol{y}_{t-1}=\mathbf{W}_{e} \operatorname{softmax}\left(\mathbf{V} \boldsymbol{h}_{t-1} \odot L\right) \]
其中 \(\odot\) 表示 element-wise 乘积,当 \(L \to \infty\) 时,其估计将会变成 \((1)\)。
特征学习的混合预训练 GAN模型训练时有难以收敛的问题,通过预训练一个标准的自编码LSTM模型来初始化LSTM参数。对于判别器,随机交换语料库句子中的两个单词来构建 tweaked sentences,判别器预训练分辨真实的和tweaked sentence。
标题:Adversarial Feature Matching for Text Generation
作者:Yizhe Zhang, Zhe Gan, etc.
发表:ICML 2017
这篇论文是上面的续作,同样使用 LSTM 作为生成器,CNN 作为判别器,通过 kernelized discrepancy metric 来匹配真实句子和合成句子的高维隐藏特征分布。这种方法可以解决对抗训练中的模式崩溃问题。
什么是模式崩溃(mode collapse)?
真实世界中的数据分布可能会有多个样本集中的“波峰”。例如,假设有一个数据集,其中包含澳大利亚中部爱丽丝泉(通常非常热)和南极南极(通常非常寒冷)的夏日温度的混合数据。数据的分布是双峰的 - 两个地区的平均温度存在峰值,两者之间存在差距。如下图。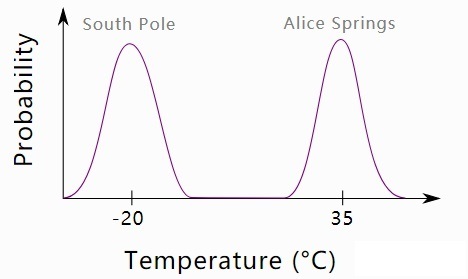
现在我们想训练一个产生合理温度值的 GAN。直观地说,我们希望生成器学会以几乎相等的概率产生热和冷的温度。然而,通常遇到的问题是模式崩溃,导致生成器仅从单一模式输出样本(例如,仅低温)。为什么会这样?可以考虑以下情形:
1、生成器学习到它可以通过产生接近南极温度的值来欺骗判别器认为它正在输出实际温度。
2、判别器通过了解所有澳大利亚温度都是真实的(不是由生成器产生的)而对生成器进行反驳,并且猜测南极温度是真实的还是虚假的,因为它们无法区分。
3、该生成器切换模式使得产生的值接近澳大利亚的温度来欺骗判别器,放弃南极模式。
4、判别器现在假设澳大利亚所有的温度都是假的,而南极的温度是真实的。
5、返回到第1步。
这种猫捉老鼠的游戏总是重复让人厌烦,生成器也从未被直接激励来覆盖这两种模式。在这种情况下,生成器在生成的样本中将表现出非常差的多样性,这限制了 GAN 的使用。
同时,模型还在Reproducing Kernel Hilbert Space(RKHS)上使用基于核的矩匹配(moment-matching),来使得真实句子和合成句子的经验分布在隐藏特征空间中有匹配的矩。
TextGAN
给定句子语料库 \(\mathcal{S}\),使用类似于特征匹配模式替代标准GAN模型中的目标函数: \[ \begin{aligned} \mathcal{L}_{D} &=\mathcal{L}_{G A N}-\lambda_{r} \mathcal{L}_{r e c o n}+\lambda_{m} \mathcal{L}_{M M D^{2}} \\ \mathcal{L}_{G} &=\mathcal{L}_{M M D^{2}} \\ \mathcal{L}_{G A N} &=\mathbb{E}_{s \sim \mathcal{S}} \log D(s)+\mathbb{E}_{z \sim p_{z}} \log [1-D(G(z))] \\ \mathcal{L}_{\text {recon }} &=\|\hat{z}-z\|^{2}, \end{aligned} \]
其中判别器最大化 \(\mathcal{L}_D\),生成器最小化 \(\mathcal{L}_G\)。 \(\mathcal{L}_{GAN}\) 是GAN中标准的目标函数。\(\mathcal{L}_{recon}\) 是原始编码和重构的隐藏编码之间的欧氏距离,\(z\) 来自先验分布 \(p_z(·)\)。\(\mathcal{L}_{M M D^{2}}\) 表示生成数据 \(\tilde{\boldsymbol{f}}\) 和真实数据句子嵌入 \(\boldsymbol{f}\) 经验分布之间的最大平均差(Maximum Mean Discrepancy)。
MMD:maximum mean discrepancy。最大平均差异。最先提出的时候用于双样本的检测(two-sample test)问题,用于判断两个分布p和q是否相同。它的基本假设是:如果对于所有以分布生成的样本空间为输入的函数f,如果两个分布生成的足够多的样本在f上的对应的像的均值都相等,那么那么可以认为这两个分布是同一个分布。现在一般用于度量两个分布之间的相似性。
MMD度量值刻画了样本集合 \(\mathcal{X}\) 和 \(\mathcal{Y}\) 在Reproducing Kernel Hilbert Space (RKHS),\(\mathcal{H}\) 上关于核函数 \(k(\cdot): \mathbb{R}^{d} \times \mathbb{R}^{d} \mapsto \mathbb{R}\) 的差别。用数学公式表示为: \[ \begin{aligned} \mathcal{L}_{M M D^{2}} &=\left\|\mathbb{E}_{x \sim \mathcal{X}} \phi(x)-\mathbb{E}_{y \sim \mathcal{Y}} \boldsymbol{\phi}(y)\right\|_{\mathcal{H}}^{2} \\ &=\mathbb{E}_{x \sim \mathcal{X}} \mathbb{E}_{x^{\prime} \sim \mathcal{X}}\left[k\left(x, x^{\prime}\right)\right] \\ &+\mathbb{E}_{y \sim \mathcal{Y}} \mathbb{E}_{y^{\prime} \sim \mathcal{Y}}\left[k\left(y, y^{\prime}\right)\right]-2 \mathbb{E}_{x \sim \mathcal{X}} \mathbb{E}_{y \sim \mathcal{Y}}[k(x, y)] \end{aligned} \tag{4} \]
模型框架图如下: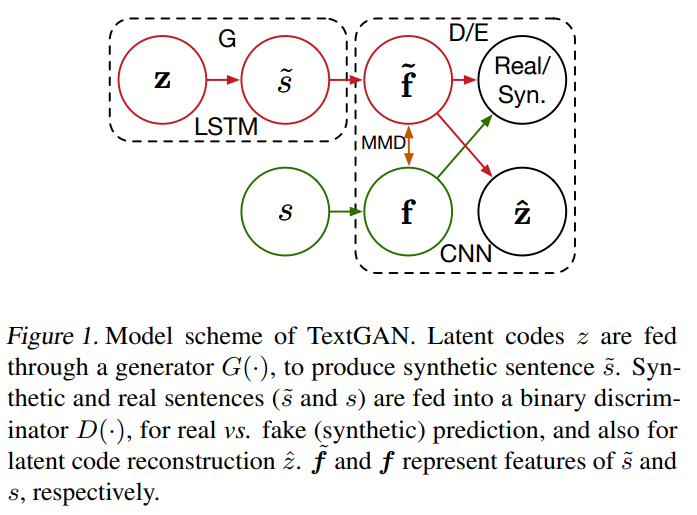
在判别器的目标函数中,(1)\(\mathcal{L}_{GAN}\) 要求 \(\tilde{\boldsymbol{f}}\) 和 \(\boldsymbol{f}\) 尽量有区别;(2)\(\mathcal{L}_{recon}\)要求 \(\tilde{\boldsymbol{f}}\) 和 \(\boldsymbol{f}\) 尽量保留用于生成句子的隐藏编码 \(z\) 的重构信息;(3)\(\mathcal{L}_{MMD^2}\) 要求判别器 \(D(\cdot)\) 选择最具有挑战性特征让生成器去匹配。这三个部分时段判别器可以生成有区分度、有代表性、有挑战性的句子特征。
MMD的使用,使得生成器尽量产生多样性的句子来匹配真实句子的变化,这一定程度上解决了模式崩溃问题。另外,GAN在训练过程中还存在收敛问题,当真实数据和生成数据相距很远时,JS散度只能产生很弱的梯度信号。在 \((4)\) 中,本质上是通过高斯核使用了神经网络嵌入来匹配句子 \(s\) 和 \(\tilde{s}\)。当和函数是共用的时,MMD metric能比较好的解决梯度消失问题。