标题:MaskGAN: Better Text Generation via Filling in the______
作者:William Fedus, Ian Goodfellow, Andrew M. Dai
发表:ICLR 2018
文本生成的神经模型常常是自回归语言模型或者seq2seq模型,这些模型通过序列采样单词生成文本,每个词的生成受之前产生词的影响。虽然这些方法在一些 benchmark 上有比较好的结果,比较适合优化 perplexity,但常会因为前段序列产生了训练数据中未出现过的单词而导致错误累计(exposure bias),产生很差的结果。而 GAN 模型解决了以上问题却对离散数据生成有着难以计算梯度的问题,因此论文提出了一个 actor-critic conditional GAN,MaskGAN,通过周围的语境填充缺失的文本进行训练,在条件和非条件的 text samples 中有着很好的效果。
MaskGAN
用 \((x_t,y_t)\) 表示输入和目标 tokens 对,< m > 表示用于遮住的 token(替代原 token),\(\hat{x_t}\) 表示被遮住的原始的 token,\(\tilde{x_t}\)表示填写的 token,它会被传递给判别器来判断真假。
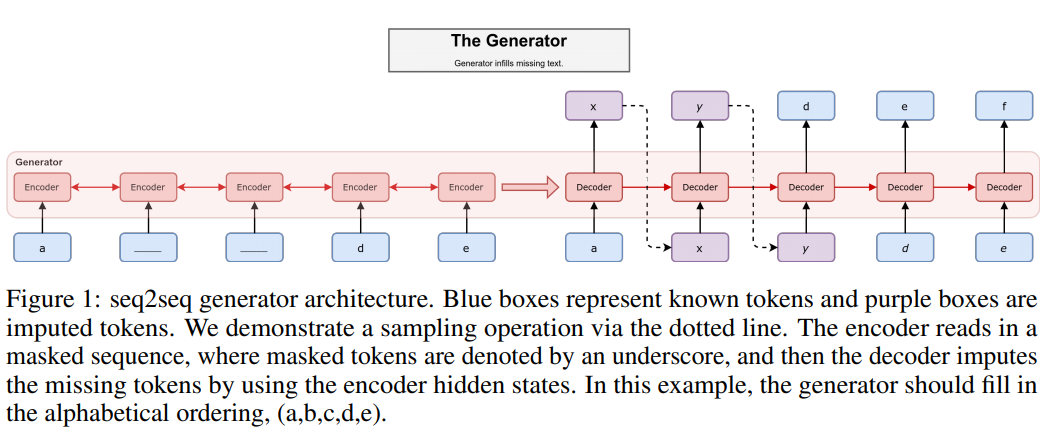
填写缺失的 tokens 需要结合之前和之后的信息,为此选择了 seq2seq 架构。生成器由编码模型和解码模型构成。对于一个离散的序列 \(\boldsymbol{x}=\left(x_{1}, \cdots, x_{T}\right)\),会随机或确定地生成一个相同长度的二元 mask,\(\boldsymbol{m}=\left(m_{1}, \cdots, m_{T}\right)\),其中 \(m_t \in \{0,1\}\),用于选择保留哪些 tokens。编码器会读入遮住后的序列,表示为 \(\boldsymbol{m}(\boldsymbol{x})\)。
在标准的语言模型中,解码器自回归地填充弄缺失的 tokens,但是现在这同时依赖于被遮住的文本 \(\boldsymbol{m}(\boldsymbol{x})\) 和目前为止已填写的 tokens。生成器将序列的分布分解为顺序的条件序列\(P\left(\hat{x}_{1}, \cdots, \hat{x}_{T} \mid \boldsymbol{m}(\boldsymbol{x})\right)=\prod_{t=1}^{T} P\left(\hat{x}_{t} \mid \hat{x}_{1}, \cdots, \hat{x}_{t-1}, \boldsymbol{m}(\boldsymbol{x})\right)\),这样的话生成一个 token 的概率可以表示为: \[ G\left(x_{t}\right) \equiv P\left(\hat{x}_{t} \mid \hat{x}_{1}, \cdots, \hat{x}_{t-1}, \boldsymbol{m}(\boldsymbol{x})\right) \]
判别器与生成器有着相同的架构,但输出是每一时刻的属于真实数据的概率标量,而不是词汇表大小的分布。判别器接收生成器填充好的序列,同时还会接收原始遮住后的序列 \(\boldsymbol{m}(\boldsymbol{x})\) 以帮助判别器做更好的判断。 \[ D_{\phi}\left(\tilde{x}_{t} \mid \tilde{x}_{0: T}, \boldsymbol{m}(\boldsymbol{x})\right)=P\left(\tilde{x}_{t}=x_{t}^{\mathrm{real}} \mid \tilde{x}_{0: T}, \boldsymbol{m}(\boldsymbol{x})\right) \]
判别器估计概率的 log 值会作为奖励: \[ r_{t} \equiv \log D_{\phi}\left(\tilde{x}_{t} \mid \tilde{x}_{0: T}, \boldsymbol{m}(\boldsymbol{x})\right) \]
模型中第三个网络是 critic network,作为判别器的补充。它用于估计 value function,是填充序列总的折扣奖励 \(R_{t}=\sum_{s=t}^{T} \gamma^{s} r_{s}\),其中 \(\gamma\) 是序列中每个位置的折扣因子。
训练
由于模型本身根据生成器的概率分布采样下一个 tokens 这一操作时不可微的,所以为了训练生成器,采用了策略梯度的方法,最大化累计奖励 \(R=\sum_{t=1}^{T} R_{t}\)。 通过对\(\mathbb{E}_{G(\theta)}[R]\) 执行梯度上升优化生成器的参数。可得其无偏估计 \(\nabla_{\theta} \mathbb{E}_{G}\left[R_{t}\right]=R_{t} \nabla_{\theta} \log G_{\theta}\left(\hat{x}_{t}\right)\),使用 critic 学习得到的 value function 作为baseline \(b_t = V^G(x_{1:t})\) 进行简化得到生成器单个 token 的梯度贡献: \[ \nabla_{\theta} \mathbb{E}_{G}\left[R_{t}\right]=\left(R_{t}-b_{t}\right) \nabla_{\theta} \log G_{\theta}\left(\hat{x}_{t}\right) \]
总的生成器梯度为 \[ \begin{aligned} \nabla_{\theta} \mathbb{E}[R] &=\mathbb{E}_{\hat{x}_{t} \sim G}\left[\sum_{t=1}^{T}\left(R_{t}-b_{t}\right) \nabla_{\theta} \log \left(G_{\theta}\left(\hat{x}_{t}\right)\right)\right] \\ &=\mathbb{E}_{\hat{x}_{t} \sim G}\left[\sum_{t=1}^{T}\left(\sum_{s=t}^{T} \gamma^{s} r_{s}-b_{t}\right) \nabla_{\theta} \log \left(G_{\theta}\left(\hat{x}_{t}\right)\right)\right] \end{aligned} \]
与传统GAN训练一样,判别器会根据以下梯度更新: \[ \nabla_{\phi} \frac{1}{m} \sum_{i=1}^{m}\left[\log D\left(x^{(i)}\right)\right]+\log \left(1-D\left(G\left(z^{(i)}\right)\right]\right. \]