标题:SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
作者:Lantao Yu, Weinan Zhang, Jun Wang, Yong Yu
发表:AAAI 2017
GAN模型在生成由离散 token 组成的句子时,判别器难以将梯度创给生成器更新参数,另外判别器只能评判整个句子,而对于生成句子的一部分,很难平衡当前分数和未来生成的句子的分数。这篇文章提出了 SeqGAN 来解决这些问题。该模型将生成器看成是强化学习中的随机策略,通过直接执行梯度策略(gradient policy)更新来绕过生成器的微分问题。模型使用GAN中判别器对整个句子评判的结果作为强化学习中的奖励信号,并用蒙特卡洛搜索将其传递给中间步的状态动作。
SeqGAN
序列生成任务定义如下。给定真实世界的一个结构化序列数据集,训练一个以 \(\theta\) 为参数的生成模型 \(G_{\theta}\) 来生成一个序列 \(Y_{1: T}=\left(y_{1}, \ldots, y_{t}, \ldots, y_{T}\right), y_{t} \in \mathcal{Y}\),其中 \(\mathcal{Y}\) 是候选 tokens 的词汇表。论文将该问题视为强化学习任务:在时间步 \(t\) ,状态 \(s\) 是当前已产生的 tokens \((y_{1}, \ldots, y_{t-1})\),动作 \(a\) 是下一个要选择的 token \(y_t\),因此策略模型 \(G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right)\) 是随机的,尽管在动作选择后状态的迁移是确定的。
另外,论文也训练了一个以 \(\phi\) 为参数的判别模型 \(D_{\phi}\) 来提供改进生成器 \(G_{\theta}\) 的指导。\(D_{\phi}(Y_{1:T})\) 表示序列 \(Y_{1:T}\) 有多大的概率来自真实的序列数据。如下图所示,判别器 \(D_{\phi}\) 使用真实序列数据作为正样本,生成器 \(G_{\theta}\) 生成的序列作为负样本进行训练。于此同时,生成器 \(G_{\theta}\) 依据判别器 \(D_{\phi}\) 给出的最终期待奖励值,使用策略梯度和蒙特卡洛搜索进行更新。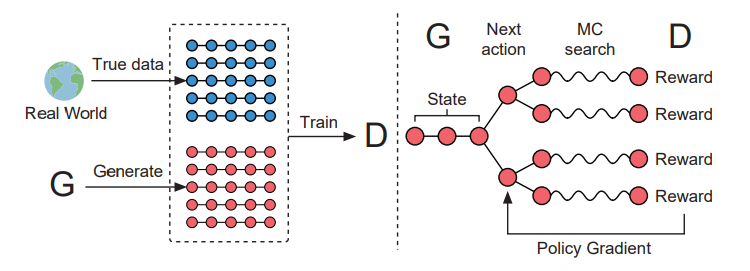
策略梯度(Policy Gradient)
当不存在中间奖励时,生产模型 \(G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right)\) 的目标就是生成从开始状态 \(s_0\) 起,最大化最终期望奖励的序列: \[ J(\theta)=\mathbb{E}\left[R_{T} \mid s_{0}, \theta\right]=\sum_{y_{1} \in \mathcal{Y}} G_{\theta}\left(y_{1} \mid s_{0}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(s_{0}, y_{1}\right) \]
其中 \(R_{T}\) 是完整序列的奖励,来自判别器 \(D_{\phi}\)。\(Q_{D_{\phi}}^{G_{\theta}}\left(s_{0}, y_{1}\right)\) 是序列的 action-value 函数,即从状态 \(s\),采取动作 \(a\),使用策略 \(G_{\theta}\)的期望累计奖励值。这与生成器想要判别器认为生成的序列是真实的这一目标一致。
所以接下来的问题就是如何估计 action-value 函数。首先,论文将判别器判断序列为真的概率 \(D_{\phi}(Y_{1:T})\) 作为奖励值,则: \[ Q_{D_{\phi}}^{G_{\theta}}\left(a=y_{T}, s=Y_{1: T-1}\right)=D_{\phi}\left(Y_{1: T}\right) \]
但是判别器只能为最终的句子提供一个奖励值,而对于每个时间步产生的句子的一部分,我们不仅应该考虑句子本身,还需要考虑未来输出的结果。就好像围棋和象棋,玩家有时会牺牲中间短暂的利益来换取长期的胜利。所以为了评估中间状态的 action-value,论文使用了带有 roll-out 策略(在论文中与生成器相同) \(G_{\beta}\) 的蒙特卡洛搜索(Monte Carlo search)来采样后半部分未知的 \(T - t\) 个 tokens。将 \(N\) 次的蒙特卡洛搜索表示为: \[ \left\{Y_{1: T}^{1}, \ldots, Y_{1: T}^{N}\right\}=\mathrm{MC}^{G_{\beta}}\left(Y_{1: t} ; N\right) \]
roll-out 算法是对于当前状态,从每一个可能的动作开始,之后根据给定的策略进行路径采样,根据多次采样的奖励总和来对当前状态的行动值进行估计。当目前的估计值基本收敛时,会根据行动值最大的原则选择动作进入下一个状态再重复上述过程。在蒙特卡洛控制中,采样的目的是估计一个完整的,最优价值函数,但是roll-out中的采样目的只是为了计算当前状态的行动值以便进入下一个状态,而且这些估计的行动值并不会被保留。在roll-out中采用的策略往往比较简单被称作 roll-out 策略 (roll-out policy)。
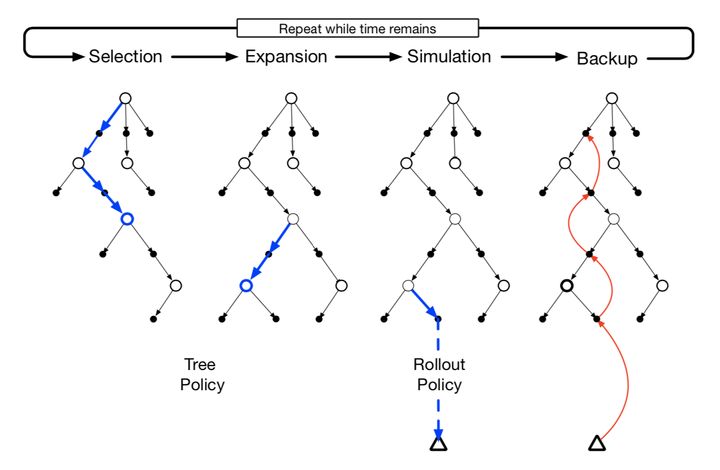
蒙特卡洛树搜索是上面提到的 roll-out 算法的拓展版,在于它会记录搜索过程中的行动值变化以便更好的采样,完整的步骤有以下四步:
1、选择:从根节点出发,根据树策略(tree policy)选择一个叶节点
2、拓展:有一定概率发生,从选择的叶节点中执行一个未执行过的行动来增加一个子节点
3、模拟:从当前叶节点开始,根据 roll-out 策略执行动作直到终止时间
4、回溯:利用本次模拟中得到的奖励和逐层更新所使用到的树内节点
使用 \(N\) 次 roll-out 策略后,会得到一批输出样。因此有: \[ \begin{array}{ll} Q_{D_{\phi}}^{G_{\theta}}\left(s=Y_{1: t-1}, a=y_{t}\right)= \left\{\begin{array}{ll} \frac{1}{N} \sum_{n=1}^{N} D_{\phi}\left(Y_{1: T}^{n}\right), Y_{1: T}^{n} \in \mathrm{MC}^{G_{\beta}}\left(Y_{1: t} ; N\right) & \text { for } t<T \\ D_{\phi}\left(Y_{1: t}\right) & \text { for } t=T \end{array}\right. \end{array} \]
使用判别器 \(D_{\phi}\) 作为奖励函数的好处是它可以动态地更新以进一步迭代地改善生成器。如果生成了一批更加真实的序列,应该重新训练生成器: \[ \min _{\phi}-\mathbb{E}_{Y \sim p_{\text {data }}}\left[\log D_{\phi}(Y)\right]-\mathbb{E}_{Y \sim G_{\theta}}\left[\log \left(1-D_{\phi}(Y)\right)\right] \]
有了新的判别器后,就可以更新生成器,基于策略的方法通过直接最大化长期的奖励来优化参数。生成器目标函数 \(J(\theta)\) 对参数 \(\theta\) 的梯度可以推导为:\[ \nabla_{\theta} J(\theta)=\sum_{t=1}^{T} \mathbb{E}_{Y_{1: t-1} \sim G_{\theta}}\left[\sum_{y_{t} \in \mathcal{Y}} \nabla_{\theta} G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1: t-1}, y_{t}\right)\right] \]
对上市构建一个无偏估计: \[ \begin{array}{l} \nabla_{\theta} J(\theta) \simeq \sum_{t=1}^{T} \sum_{y_{t} \in \mathcal{Y}} \nabla_{\theta} G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1: t-1}, y_{t}\right) \\ =\sum_{t=1}^{T} \sum_{y_{t} \in \mathcal{Y}} G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right) \nabla_{\theta} \log G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1: t-1}, y_{t}\right) \\ =\sum_{t=1}^{T} \mathbb{E}_{y_{t} \sim G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right)}\left[\nabla_{\theta} \log G_{\theta}\left(y_{t} \mid Y_{1: t-1}\right) \cdot Q_{D_{\phi}}^{G_{\theta}}\left(Y_{1: t-1}, y_{t}\right)\right] \end{array} \] 其中 $ Y_{1: t-1}$ 是从 \(G_{\theta}\) 中采样观察到的中间状态,期望 \(\mathbb{E}[\cdot]\) 可以通过采样方法估计,然后就可以更新生成器的参数了: \[ \theta \leftarrow \theta+\alpha_{h} \nabla_{\theta} J(\theta), \]
算法
