标题:Long Text Generation via Adversarial Training with Leaked Information
作者:Jiaxian Guo, Sidi Lu, etc.
发表:AAAI 2018
将生成器视为强化学习过程,使用判别器指导生成器训练的GAN模型在文本生成上取得了不错的结果。但是,标量指导信号只有在整个文本生成完后才能由判别器给出,且信号信息量不大,缺少了生成过程中文本结构的中间信息。所以在生成较长的文本时(超过20个单词)效果并不好。该论文提出了一个新的架构 LeakGAN,来解决长文本生成的问题。LeakGAN 允许判别器向生成器泄露抽取到的高层次特征来帮助生成器的学习。在生成过程的每一步中,生成器通过 MANAGER 模型将当前文本抽取到的特征作为输入,输出一个隐藏向量来指导 WORKER 模型生成下一个单词。
LeakGAN
LeakGAN 用于解决指导信号(判别器给出的概率值)信息量不够以及稀疏的问题,其模型框架如下图所示: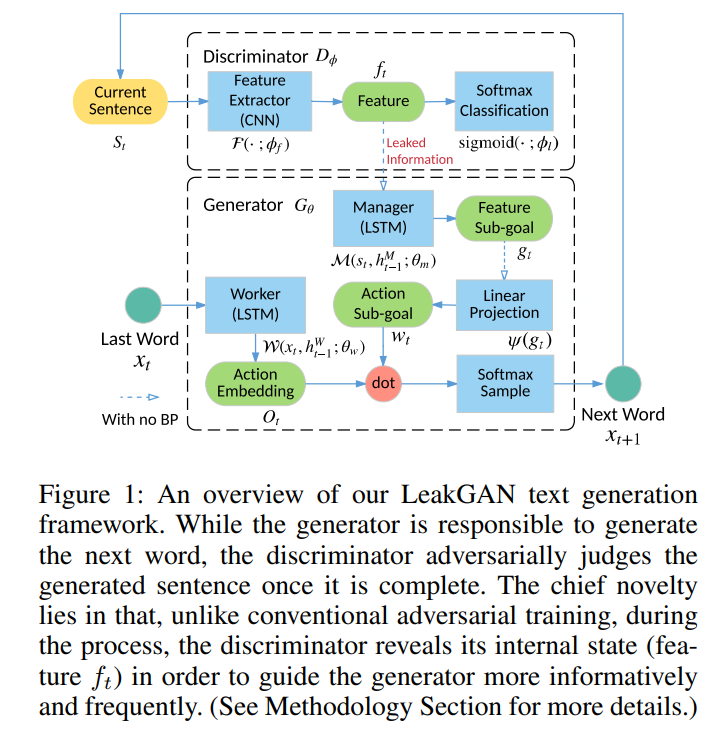
判别器泄露特征
不同于传统强化学习模型的奖励函数是一个黑盒,该模型使用判别器 \(D_{\phi}\) 来学习奖励函数。因为 \(D_{\phi}\) 本身是一个神经网络,可以被分解成一个特征提取器 \(\mathcal{F}\left(\cdot ; \phi_{f}\right)\) 和一个最后带有权重向量 \(\phi_l\) 的 sigmoid 分类层。对于输入 \(s\),则有: \[ D_{\phi}(s)=\operatorname{sigmoid}\left(\phi_{l}^{\top} \mathcal{F}\left(s ; \phi_{f}\right)\right)=\operatorname{sigmoid}\left(\phi_{l}^{\top} f\right) \]
其中 \(\phi = (\phi_f,\phi_l)\),\(\operatorname{sigmoid}(z) = 1/(1+e^{-z})\)。\(f=\mathcal{F}\left(s ; \phi_{f}\right)\) 是判别器对输入 \(s\) 提取的特征向量,将会被泄露给生成器 \(G_{\theta}\)。对于给定的 \(D_{\phi}\) 每个状态 \(s\) 的奖励值主要取决于提取到的特征 \(f\)。因此,从 \(D_{\phi}\) 获取高的奖励值等价于从提取特征的空间 \(\mathcal{F}\left(\boldsymbol{S} ; \phi_{f}\right)=\left\{\mathcal{F}\left(s ; \phi_{f}\right)\right\}_{s \in \boldsymbol{S}}\) 中寻找高奖励的区域。相较于标量信号 \(D_{\phi}(s)\),特征向量 \(f\) 是一个更具特征的指导信号。
生成器的层级结构
在生成过程的每一步 \(t\) 中,为了利用从 \(D_{\phi}\) 中泄露的信息 \(f_t\),生成器使用了层级的强化学习模型架构。具体的,包括 MANAGER 模型,一个以提取到的特征向量 \(f_t\) 作为输入,输出目标向量 \(g_t\) 的 LSTM 网络,和 WORKER 模型,接收目标函数 \(g_t\) 指导下一个单词的生成。
MANAGER 产生目标函数 \(g_t\) 的方法为: \[ \begin{aligned} \hat{g}_{t}, h_{t}^{M} &=\mathcal{M}\left(f_{t}, h_{t-1}^{M} ; \theta_{m}\right), \\ g_{t} &=\hat{g}_{t} /\left\|\hat{g}_{t}\right\| \end{aligned} \]
其中 \(\mathcal{M}\left(\cdot; \theta_{m}\right)\) 表示 LSTM 实现的 MANAGER 模型,\(h_{t}^{M}\) 是 LSTM 的隐层向量。
为了利用 MANAGER 产生的目标向量,会用权重矩阵 \(W_{\psi}\) 对最近的 \(c\) 个目标向量加权平均得到 \(k\) 为的目标嵌入向量 \(w_t\): \[ w_{t}=\psi\left(\sum_{i=1}^{c} g_{t-i}\right)=W_{\psi}\left(\sum_{i=1}^{c} g_{t-i}\right) \]
WORKER 模型会用当前单词 \(x_t\) 作为输入,输出一个矩阵 \(O_t\),再与目标嵌入向量 \(w_t\) 做矩阵乘法,使用 softmax 确定最终的动作分布空间: \[ \begin{aligned} O_{t}, h_{t}^{W} &=\mathcal{W}\left(x_{t}, h_{t-1}^{W} ; \theta_{w}\right) \\ G_{\theta}\left(\cdot \mid s_{t}\right) &=\operatorname{softmax}\left(O_{t} \cdot w_{t} / \alpha\right) \end{aligned} \]
生成器的训练
训练方法与 SeqGAN 类似,MANAGER 模型的梯度定义为: \[ \nabla_{\theta_{m}}^{\mathrm{adv}} g_{t}=-Q_{\mathcal{F}}\left(s_{t}, g_{t}\right) \nabla_{\theta_{m}} d_{\cos }\left(f_{t+c}-f_{t}, g_{t}\left(\theta_{m}\right)\right) \]
其中\(Q_{\mathcal{F}}\left(s_{t}, g_{t}\right)=Q\left(\mathcal{F}\left(s_{t}\right), g_{t}\right)=Q\left(f_{t}, g_{t}\right)=\mathbb{E}\left[r_{t}\right]\) 可通过蒙特卡洛搜索估计。\(d_{cos}\) 代表特征表示的改变和 MANAGER 生成的目标向量间的余弦相似度,直觉上,损失函数要求在得到高奖励同时,目标向量匹配特征空间的转移。于此同时,WORKER使用 REINFORCE 算法最大化奖励: \[ \begin{aligned} & \nabla_{\theta_{w}} \mathbb{E}_{s_{t-1} \sim G}\left[\sum_{x_{t}} r_{t}^{I} \mathcal{W}\left(x_{t} \mid s_{t-1} ; \theta_{w}\right)\right] \\ =& \mathbb{E}_{s_{t-1} \sim G, x_{t} \sim \mathcal{W}\left(x_{t} \mid s_{t-1}\right)}\left[r_{t}^{I} \nabla_{\theta_{w}} \log \mathcal{W}\left(x_{t} \mid s_{t-1} ; \theta_{w}\right)\right] \end{aligned} \]
可以通过采样状态 \(s_{t-1}\) 和动作 \(x_t\) 来估计。由于 WORKER 受 MANAGER 产生的方向的指导,WORKER 本质的奖励定义为: \[ r_{t}^{I}=\frac{1}{c} \sum_{i=1}^{c} d_{\cos }\left(f_{t}-f_{t-i}, g_{t-i}\right) \]
在实际训练前,会先对生成器 \(G_{\theta}\) 进行预训练。