6.17
- torch.tensor和np.array类似,可以互相转换
- tensor.shape()获取大小,view()修改大小
- broadcasting自动改变维度相加减
- 如果要求gradient可以自动建图
- pytorch提供to(device)来确定运行设备
- 自动求gradient使用backward()
- torch.nn.Module, 如nn.Linear(d_in, d_out)
- Activation function如nn.ReLU()
6.18
- torch.nn.Sequential(model1, model2...)一系列模型
- param = model.parameters() for循环
- 损失函数 nn.MSELoss()等
- torch.optim
optim = torch.optim.SGD(model.parameters(), lr = 1e-2) - Dataset 重写__init__, __len__, __getitem__
- DataLoader(dataaset, batch_size=4, shuffle=True, num_workers=4)
- detach()不计算tensor的梯度,使用with torch.no_grad()在预测时不计算梯度
- 默认梯度会累加,通常在backward之前调用zero_grad()
以下作业内容来自李宏毅老师机器学习课程
6.19 CNN图片分类
分为训练数据、验证数据和测试数据,图片和类别均有编号。
数据处理
在训练时可以通过水平翻转、旋转等操作进行数据增强,测试时不需要数据增强 1
2
3
4
5
6training_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), # 将图片随机水平翻转
transforms.RandomRotation(15), # 随机旋转图片
transforms.ToTensor(), # 将图片转成Tensor,并把数值normalize到[0,1]
])1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
batch_size = 128
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
定义模型
模型继承nn.Module,模型的架构和forward函数需要自己定义 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU()
nn.MaxPool2d(2, 2, 0),
...
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU()
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
训练模型
1 | model = Classifier().cuda() |
6.21 RNN
给定一个语句,判断它有没有恶意(负面标1,正面标0)。有带标签的训练数据和无标签的训练数据,还有测试数据集。
训练Word Embedding模型
1 | #w2v.py |
数据处理
- 读取word embedding的模型
- 额外增加
<PAD>和<UNK>两个特殊word的embedding - 构建word2idx的dictionary,idx2word的list,word2vector的list
- 对每一个句子处理时要将其截断或补充至相同长度
定义Dataset
1 | import torch |
定义模型
1 | import torch |
训练模型
1 | import torch |
6.22 CNN Explaination
Saliency map
计算loss对图像每一个像素的偏微分值,代表每个像素的重要性。将每个像素的偏微分值在同一个图中画出来,就可以看出哪些位置是模型判断的重要依据。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def normalize(image):
return (image - image.min()) / (image.max() - image.min())
def compute_saliency_maps(x, y, model):
model.eval()
x = x.cuda()
x.requires_grad_() # 告知pytorch输入x需要计算gradient
y_pred = model(x)
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(y_pred, y.cuda())
loss.backward()
saliencies = x.grad.abs().detach().cpu()
saliencies = torch.stack([normalize(item) for item in saliencies])
return saliencies
Filter explaination
探究某一个filter到底认出了什么,可以通过 - Filter activation:挑选几张图片,看看图片中的哪些位置会activate该filter - Filter visualization:怎样的image可以最大程度的activate该filter 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def normalize(image):
return (image - image(min)) / (image.max() - image.min())
layer_activations = None
def filter_explaination(x, model, cnnid, filterid, iteration=100, lr=1):
# x: 输入的图片们
# cnnid, filterid: 指定第cnnid个cnn中第filterid个filter
model.eval()
def hook(model, input, output):
global layer_activations
layer_activations = output
# 告诉pytorch当forward过了第cnnid层cnn后,先调用hook,再继续forward
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x.cuda())
filter_activation = layer_activation[:, filterid, :, :].detach().cpu()
# 找出最大程度上activate该filter的图片
x = x.cuda()
x.requires_grad_()
optimizer = Adam([x], lr=lr)
for iter in range(iteration):
optimizer.zero_grad()
model(x)
objective = -layer_activations[:, filterid, :, :].sum()
objective.backward()
optimizer.step()
filter_visualization = x.detach().cpu().squeeze()[0]
hook_handle.remove()
return filter_activations, filter_visualization
Lime
用来判断图片中的各个segment对模型判断的影响,可以调包实现,具体实现两个函数 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def predict(input):
model.eval()
input = torch.FloatTensor(input).permute(0, 3, 1, 2)
output = model(input.cuda())
return output.detach().cpu().numpy()
def segmentation(input):
return slic(input, n_segments=100, compactness=1, sigma=1)
for idx, (image, label) in enumerate(zip(images.permute(0, 2, 3, 1).numpy(), labels)):
...
explainer = lime_image.LimeImageExplainer()
explaination = explainer.explain_instance(image=x, classifier_fn=predict, segmentation_fn=segmentation)
lime_img, mask = explaination.get_image_and_mask(
label=label.item(),
positive_only=False,
hide_rest=False,
num_features=11,
min_weight=0.05
)
...
6.23 Adverdarial Attack
网络攻击一种简单且有效的方法是Fast Gradient Sign Method (FGSM),它计算损失函数对攻击图片的gradient,根据gradient的符号来判断是加上还是减去lerning rate。通过设定较大的learning rate后再纠正可以在一次更新后取得很好的攻击效果。

执行FGSM攻击
1 | class Attacker: |
6.24 - 6.25 Network Compression
有限的存储空间和计算能力,如移动设备,所以需要将Network变小。
Network Pruning
大部分时候Network都是over-parameterized的。对于一个大的Network,评估权重和神经元的重要性,移除不重要的权重或神经元,之后进行Fine-tune来调整恢复网络
为什么不简单的训练一个小的Network呢?
小的Network更难训练,大的Network更容易optimize,达到global minimum。大乐透假说(Lottery Ticket Hypothesis),大的Network包含很多的小Network,更容易训练起来(不一定???可以直接训练小网络???)。
prune weight会导致Network不规则,无法进行矩阵运算,所以训练速度可能更慢,而prune neural不会。
Knowledge Distillation
用小的Network来学习大的Network,以大的Network的输出作为target。这种方法可以将Ensemble的模型缩小为一个模型。
在Teacher model做softmax时可以取一个Temperature来均衡各个标签的概率。
\[ \text { Loss }=\alpha T^{2} \times K L\left(\frac{\text { Teacher's Logits }}{T} \| \frac{\text { Student's Logits }}{T}\right)+(1-\alpha)(\text { Original Loss }) \]
1 | def loss_fn_kd(outputs, labels, teacher_outputs, T=20, alpha=0.5): |
Parameter Quantization
将参数用更少的bit来表示,或同一参数范围的用特定bit表示。最极端的比如Binary Weight,参数都+1或者-1。
torch.FloatTensor预设是32-bit,最低可容忍16bit。numpy有float16,float32,float64,可以将32bit的tensor转换成16-bit的ndarray存起来。也可以将32bit的Tensor转为8bit存储,转换方式为:
\[ W^{\prime}=\operatorname{round}\left(\frac{W-\min (W)}{\max (W)-\min (W)} \times\left(2^{8}-1\right)\right) \]
Architecture Design
比如在两个全连接层中插入一个linear layer,参数会变少
Depthwise Separable Convolution:1.Depthwise Convolution:每个filter处理一个channel。2.Pointwise Convolution:使用多个1X1的filter
1 | # 一般的Convolution,weight大小 = in_chs * out_chs * kernel_size^2 |
Dynamic Computation
在运算资源不足时动态调整计算,先求有再求好。可以训练多个模型或者使用中间层处理
6.26-6.29 Seq2seq
Generation
使用RNN模型可以生成句子或者图片
Conditional Generation
比如Image Caption Generation,先通过CNN将图片转成Vector,再将vector丢入RNN。还有Machine translation/Chat-bot,分为Encoder和Decoder,参数可以不一样也可以一样。
Attention(Dynamic Conditional Generation)
以机器翻译为例,使用一个向量计算与句子中各部分的匹配度,得到Encoder向量丢入Decoder。
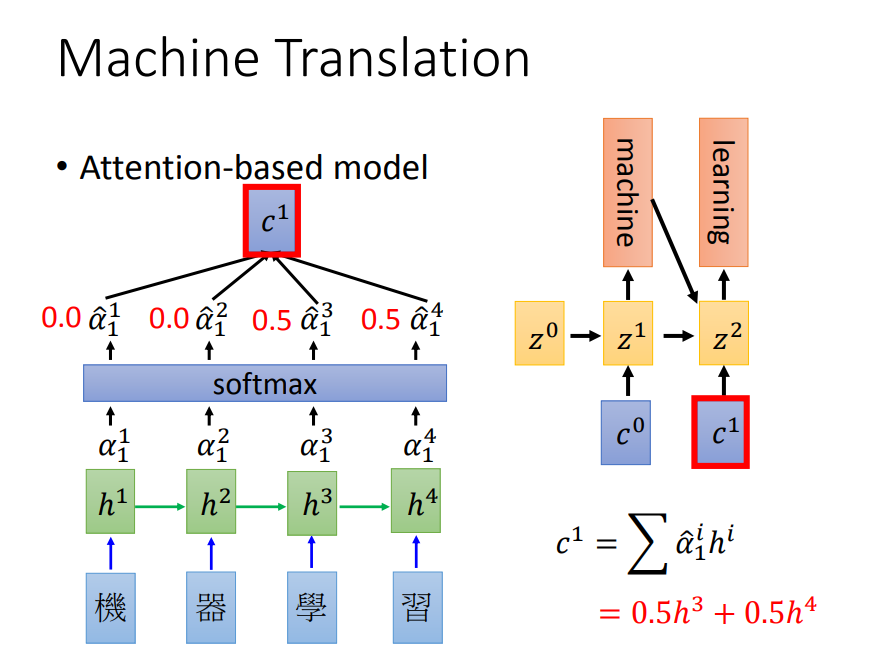
Tips
- 各部分所收到的总的Attention应该比较均匀,所以可以增加attention regularization。
- 在RNN中如果在训练时只用标签作指导可能会出现test时的误差累计,可以使用Scheduled Sampling,通过几率选择是看标签还是模型输出。
- 使用贪心的策略选择输出的句子可能不是一个得分最高的路径,可以使用Beam Search选取得分最高的路径。
- 在评价结果好坏的时候是从Object level还是Component level。
- 使用强化学习来进行训练
评价指标BLUE@1
\[ Precision = 正确字数/c \]
\[ \mathrm{BP}=\left\{\begin{array}{ll} 1 & \text { if } c>r \\ e^{(1-r / c)} & \text { if } c \leq r \end{array}\right. \]
\[ \text{BLEU@1} = \mathrm{BP} * Precision \]
比如对于正解 ['我', '不', '知', '道', '我', '有', '沒', '有', '时', '间', '。']的预测 ['我', '不', '知', '道', '我', '是', '否', '时', '间', '。'],BLEU@1得分为\(e^{1-\frac{11}{10}} * \frac{8}{10}=0.723869\)。
机器翻译代码实现
Encoder

1 | class Encoder(nn.Module): |
Decoder
Decoder是另一个RNN,在简单的seq2seq decoder中,仅使用Encoder每一层最后的隐层状态(“content vector”)来进行解码,而Encoder的输出通常用于Attention Mechanism。
输入:前一次解码出来的单词的整数表示 输出:hidden:根据输入和前一次的隐藏状态,现在的隐藏状态更新的结果。output:每个字有多少概率是这次解码的结果。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class Decoder(nn.Module):
def __init__(self, cn_vocab_size, emb_dim, hid_dim, n_layer, dropout, isatt):
super().__init__()
self.cn_vocab_size = cn_vocab_size
self.hid_dim = hid_dim * 2
self.n_layers = n_layers
self.embeding = nn.Embedding(cn_vocab_size, config.emb)
self.isatt = isatt
self.attention = Attention(hid_dim)
self.input_dim = emb_dim
self.rnn = nn_GRU(self.input_dim, self.hid_dim, self.n_layer, dropout=dropout, batch_first=True)
self.embedding2vocab1 = nn.Linear(self.hid_dim, self.hid_dim * 2)
self.embedding2vocab2 = nn.Linear(self.hid_dim * 2, self.hid_dim * 4)
self.embedding2vocab3 = nn.Linear(self.hid_dim * 4, self.cn_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size, vocab size]
# hidden = [batch size, n layers * directions, hid dim]
# Decoder 只会是单向,所以 directions=1
input = input.unsqueeze(1)
embedded = self.dropout(self.embedding(input))
if self.isatt:
attn - self.attention(encoder_outputs, hidden)
# TODO: 可将attn与输入相加或是接在后面,需要注意维度变化
output, hidden = self.rnn(embedded, hidden)
# 将RNN的输出转为每个词出现的概率
output = self.embedding2vocab1(output.squeeze(1))
output = self.embedding2vocab2(output)
prediction = self.embedding2vocab3(output)
return prediction, hidden
Attention
当输入过长,或者单独靠“content vector”无法取得整个输入的意思时,用Attention方法为Decoder提供更多的信息。主要是根据现在的Decoder hidden state,用Neural Network/Dot Product等方法计算与Encoder outputs之间的关系,再对计算出来的数值做softmax,,最后根据softmax的值对Encoder outputs做weight sum。
Seq2Seq
由Encoder和Decoder组成,接收输入传给Encoder,将Encoder的输出传给Decoder,不断地将Decoder的输出传回Decoder进行解码,当解码完成后将Decoder的输出传回。
1 | class Seq2Seq(nn.Module): |