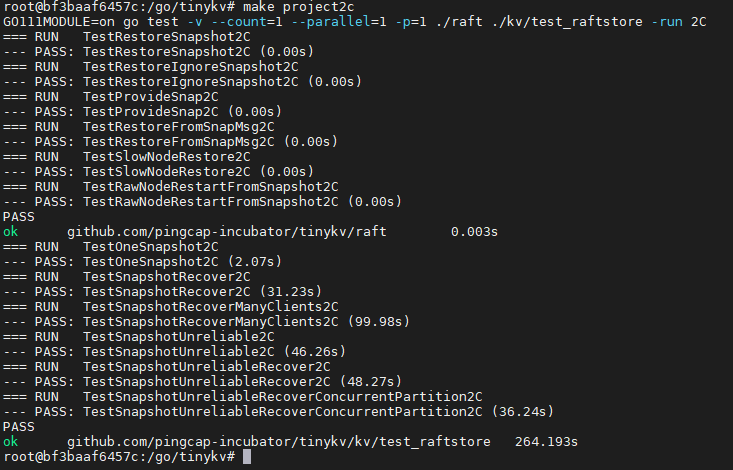
要实现一个分布式的KV数据库,那么保证各数据库中数据的一致性就非常重要了。Project2主要就是使用一致性算法Raft实现一个高可用的KV server,主要分为三个部分:
- 实现基础的Raft算法
- 在Raft的基础上构建一个容错的KV server
- 支持raftlog的垃圾回收和快照
Part A
Part A实现基础的raft算法,需要补充的代码位于raft/,这一部分同样可以拆分为三个部分:
- Leader选举
- 日志复制
- Raw node接口
首先来看看代码的基本框架,最顶层的RawNode是Raft的一个包装,它的定义为
1 | type RawNode struct { |
而Raft则是Raft算法的主要结构体:
1 | type Raft struct { |
其中具体存储日志信息的是RaftLog:
1 | type RaftLog struct { |
在RaftLog中使用Storage作为持久化存储,它实际是一个接口: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25type Storage interface {
// InitialState returns the saved HardState and ConfState information.
InitialState() (pb.HardState, pb.ConfState, error)
// Entries returns a slice of log entries in the range [lo,hi).
// MaxSize limits the total size of the log entries returned, but
// Entries returns at least one entry if any.
Entries(lo, hi uint64) ([]pb.Entry, error)
// Term returns the term of entry i, which must be in the range
// [FirstIndex()-1, LastIndex()]. The term of the entry before
// FirstIndex is retained for matching purposes even though the
// rest of that entry may not be available.
Term(i uint64) (uint64, error)
// LastIndex returns the index of the last entry in the log.
LastIndex() (uint64, error)
// FirstIndex returns the index of the first log entry that is
// possibly available via Entries (older entries have been incorporated
// into the latest Snapshot; if storage only contains the dummy entry the
// first log entry is not available).
FirstIndex() (uint64, error)
// Snapshot returns the most recent snapshot.
// If snapshot is temporarily unavailable, it should return ErrSnapshotTemporarilyUnavailable,
// so raft state machine could know that Storage needs some time to prepare
// snapshot and call Snapshot later.
Snapshot() (pb.Snapshot, error)
}MemoryStorage实现接口: 1
2
3
4
5
6
7
8
9
10
11type MemoryStorage struct {
// Protects access to all fields. Most methods of MemoryStorage are
// run on the raft goroutine, but Append() is run on an application
// goroutine.
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
// ents[i] has raft log position i+snapshot.Metadata.Index
ents []pb.Entry
}raft\的整体结构如下图所示:
Leader选举
该部分主要是实现 Raft 5.2领导人选举,由于算法本身涉及到的细节比较多,并且对框架代码不是很熟悉,一开始就有无从下手的感觉,所以基本上是面向测试编程,运行make project2aa来执行测试代码,根据测试代码的思路以及出错的位置来补充完善代码直到通过所有测试,现总结该部分如下:
首先完善创建各个结构体的函数,比如newRaft()、newLog(),然后完善becomeFollower()、becomeCandidate()、becomeLeader()函数对Raft状态进行转换。接着实现逻辑时钟函数tick(),来对心跳包和选举进行计时并判断是否超时。需要实现的最核心的函数是Step(),它对Raft收到的各种消息进行处理:
1 | func (r *Raft) Step(m pb.Message) error { |
需要处理的消息类型主要有:
1 | // Some MessageType defined here are local messages which not come from the network, but should |
在代码实现和消息处理的过程中有很多需要注意的细节:
- 在收到
MsgAppend消息后,若当前节点 term 小于消息中的 term,则更新 term 并将状态转为 Follower - 当节点启动时,应该处于 Follower 状态
- 如果 Leader 的心跳包计时达到后,应向其他节点发送
MsgHeartbeat消息 - 当一段时间 Follower 没有收到 Leader 消息或者 Candidate 没有赢得选举,则会增加当前 term,转为 Candidate 状态,开始选举(为自己投票,并请求其他节点投票)
- 在 Leader 选举中,只有赢得大多数节点的选票才能当选 Leader
- 每个 follower 在一个 term 中只会根据先来先服务的原则为一个 Candidate 投票
- 在 Candidate 等待投票的过程中,如果收到了其他节点发来的
MsgAppend消息,且消息的 term 至少和当前节点 term 一样大,则 Candidate 承认该 Leader 的合法性并转为 Follower 状态 - 如果多个节点同时发起选举则可能导致选票被瓜分而无法成功选出 Leader,因此在选举冲突后应该在原来的选举超时限制上增加一个随机值
- 如果 Candidate 的日志比没有当前节点新(term更小或相同term下index更小),则当前节点拒绝投票
还有很多函数使用以及结构体赋值等等BUG都可以在运行测试时找出来填补,最终一个个Debug后可以成功通过make project2aa
日志复制
这一部分主要是实现Raft5.3 日志复制,涉及到日志复制的很多细节,拖的时间有点长。同样的是面对测试编程,通过测试来了解需要实现哪些功能,然后疯狂解决测试中出现的Bug。
该部分与前面的领导人选举实现的模块是一样的,涉及raft.go和log.go两个文件。主要是增加了对MsgAppend和MsgAppendResponse两类消息的处理,即 Leader 节点会接收客户端对数据库的操作并将其添加到自己的日志中,Leader 会将这些日志条目通过MsgAppend消息并行地发送给其他节点以保证数据库的一致性,其他节点则通过MsgAppendResponse消息告知 Leader 日志的复制是否成功。
日志同步
Leader的重要任务就是保证Follower的日志和自己同步,它会记录其他节点下一接收日志的索引Next。在节点成功当选为Leader后,会将其他节点的Next都置为自己日志的LastIndex + 1,并Propose一条空日志发送给其他节点,在发送的MsgAppend消息中会附带新增日志的前一条日志的LogTerm和Index。接收到该消息的节点会根据LogTerm和Index判断自己的日志是否和Leader的相匹配,如果不同则拒绝添加日志,Leader会减小该节点的Next并重新发送索引Next到LastIndex的日志直到达到同步。在平时附加日志时(通过MsgAppend消息)以及心跳包中(MsgHeartbeat)也会通过以上方法保证日志的同步。
1 | func (r *Raft) becomeLeader() { |
日志提交
当日志被安全地复制到了大多数节点,则日志可以被提交。Leader存储了每个节点与自己匹配日志的最大索引Match,如果大多数Match都大于某条日志的Index,则该日志可以被提交。如果有新的日志被提交,Leader需要更新committed并发送MsgAppend消息更新Follower的committed。
1 | func (r *Raft) handleAppendResponse(m pb.Message) { |
测试和Bug
在完成Project过程中不断通过make project2ab进行测试,最终目标也是通过测试:
在测试过程中会有很多坑,整个也是个填坑的过程,比如:
- 在leader节点更新完committed后需要sendAppend空内容更新follower节点committed
- 在raft.go中,接收到的entity不会被马上写入storage,在实现RaftLog的Term()函数不能直接使用storage的Term()
- Leader不会提交之前任期的日志
- Prs需要存储自身节点的信息,在handlePropose()中需更新
- 在newRaft()中,需要根据storage中hardState的信息设置vote、term和commit
- 不能使用Next来判断日志条目被follower复制(初始Next不一定正确),需要用Match(初始化为0)
- 心跳包也需要回复,可以根据心跳包的回复来更新follower的日志
- 同一个复制日志的信息的回复只能被处理一次
- 关于Storage和RaftLog的区别
- 如果附加日志为空,follower的commit应为index(而不是lastIndex)和commit中的最小值
Raw node接口
raft/rawnode.go中的raft.RawNode是为上层应用提供的接口:
1 | type RawNode struct { |
它包含了raft.Raft并且提供了一些函数如Rawnode.Tick()和Rawnode.Step(),并且还提供了RawNode.Proposal()来让上层应用附加新的raft日志。在客户端提出一个操作请求后,raft.Raft需要做的有:
- 给其他节点发送消息
- 保存日志信息到持久化存储中
- 保存状态信息如term、commit index、vote等
- 将日志中的操作应用在状态机中
- ……
但是这些操作并不是在Raft中立即执行的,他们被包含在Ready结构体中并通过RawNode.Ready()返回给上层逻辑处理,上层在处理完获取到的Ready内容后调用RawNode.Advance()来更新raft.Raft的应用日志索引和存储日志索引等状态。
Ready结构体主要包含的内容有:
1 | type Ready struct { |
也就是需要保存的节点状态、应用的日志、存储的日志、保存的快照以及处理的消息,这些是一个Raft系统正常运转所需要处理的内容。我们在RawNode.Ready()中根据节点的实际信息来构建ready结构体,在RawNode.Advance()中更新所有内容处理后的状态和索引信息。
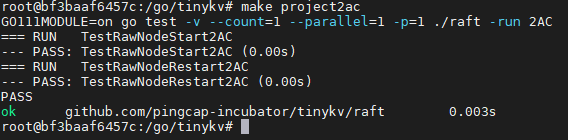
make project2ac通过测试
Part B
Part B 的目标是使用之前实现的Raft算法来构建一个可容错的键值存储服务,实际上就是包含多个键值服务器,使用Raft算法来进行复制的复制状态机。
在 TiKV 中,数据按照 key 的范围划分成了大致相等的切片(Region),每一个切片会有多个副本(通常是3个),其中一个副本是Leader,提供读写服务。各个副本分布在不同的存储节点(Store)中,每个实际的服务器(TiKV node)可以有多个store。
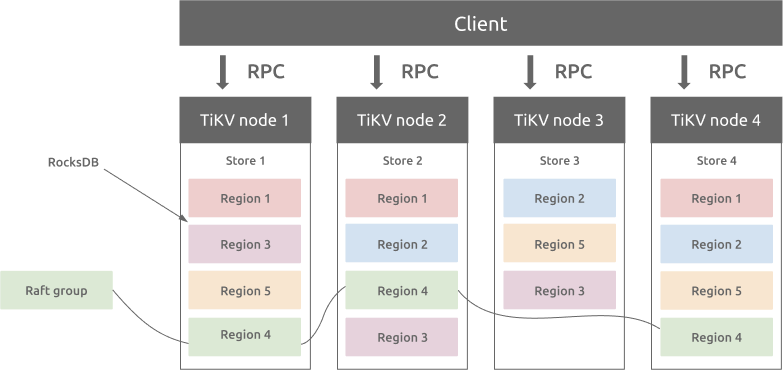
类似的,TinyKV中使用了Store、Peer和Region的概念,Store代表tinykv服务器实例,Peer代表运行在Store上的Raft节点,Region是一系列Peers的集合,也称为Raft Group。在Project2中,只考虑每个Store上一个Peer,总共一个Region的简单情况。

在Project1中,我们实现过单机的键值存储StandaloneStorage,直接读写底层的存储引擎,但是在这一部分我们要重新实现Storage接口,也就是RaftStorage:
1 | type RaftStorage struct { |
RaftStorage中Raft一致性算法的实现主要使用的是RaftStore,它在启动时会创建一系列线程处理不同的任务,其中就包括负责处理Raft的线程raftWorker 1
2
3
4
5
6
7
8
9type Raftstore struct {
ctx *GlobalContext
storeState *storeState
router *router
workers *workers
tickDriver *tickDriver
closeCh chan struct{}
wg *sync.WaitGroup
}RaftStorage的Reader和Write方法时,它实际上会通过raftWorker中 的raftCh接收通道向raftstore发送RaftCmdRequest(包含Get/Put/Delete/Snap四种基本的操作类型),当命令在raft中被提交以及执行后,会返回结果给RaftStorage,这样也就保证了读写操作在多节点中的一致性。
实现 peer storage
PeerStorage是替代Part A中MemoryStorage进行实际存储的结构体: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19type PeerStorage struct {
// current region information of the peer
region *metapb.Region
// current raft state of the peer
raftState *rspb.RaftLocalState
// current apply state of the peer
applyState *rspb.RaftApplyState
// current snapshot state
snapState snap.SnapState
// regionSched used to schedule task to region worker
regionSched chan<- worker.Task
// generate snapshot tried count
snapTriedCnt int
// Engine include two badger instance: Raft and Kv
Engines *engine_util.Engines
// Tag used for logging
Tag string
}1
2
3
4
5
6
7
8
9type Engines struct {
// Data, including data which is committed (i.e., committed across other nodes) and un-committed (i.e., only present
// locally).
Kv *badger.DB
KvPath string
// Metadata used by Raft.
Raft *badger.DB
RaftPath string
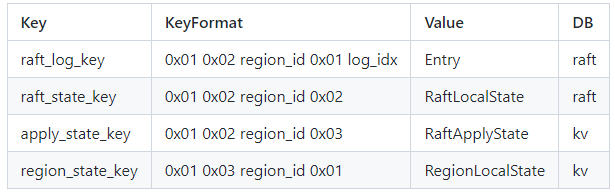
}PeerStorage除了存储raft日志和实际的数据外,也会存储一些非常重要的元信息,如:
- RaftLocalState:存储当前Raft的HardState和最后的日志索引
- RaftApplyState:存储Raft最后应用的日志索引和截断的日志信息
- RegionLocalState:存储Region的信息和当前Store对应的Peer状态
这些状态被存在raftdb和kvdb中,他们的key的编码方式如下图所示,在框架代码kv/raftstore/meta中已经实现了编码函数,在实际存储过程中可以直接调用。
在这一部分需要实现的函数是PeerStorage.SaveReadyState,这个函数将raft.Ready中的日志和状态等信息存储进badger数据库中。在存储日志时需要删掉后面可能存在的无效日志,而状态信息则调用对应的编码函数获取key值进行写入。在实际写数据的时候使用WriteBatch结构体,它提供了函数对数据一次性写入,提升效率。
1 | func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) { |
实现 Raft ready process
在框架代码中raftWorker负责处理Raft信息: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28func (rw *raftWorker) run(closeCh <-chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
var msgs []message.Msg
for {
msgs = msgs[:0]
select {
case <-closeCh:
return
case msg := <-rw.raftCh:
msgs = append(msgs, msg)
}
pending := len(rw.raftCh)
for i := 0; i < pending; i++ {
msgs = append(msgs, <-rw.raftCh)
}
peerStateMap := make(map[uint64]*peerState)
for _, msg := range msgs {
peerState := rw.getPeerState(peerStateMap, msg.RegionID)
if peerState == nil {
continue
}
newPeerMsgHandler(peerState.peer, rw.ctx).HandleMsg(msg)
}
for _, peerState := range peerStateMap {
newPeerMsgHandler(peerState.peer, rw.ctx).HandleRaftReady()
}
}
}raftWorker收到消息后,消息中对应的peer会被包装进peerMsgHandler,首先对消息(MsgTypeTick, MsgTypeRaftCmd, MsgTypeRaftMessage)调用HandleMsgs处理,然后调用HandleRaftReady获取Ready信息处理。
Raft的处理步骤可以概括为: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15for {
select {
case <-s.Ticker:
Node.Tick()
default:
if Node.HasReady() {
rd := Node.Ready()
saveToStorage(rd.State, rd.Entries, rd.Snapshot)
send(rd.Messages)
for _, entry := range rd.CommittedEntries {
process(entry)
}
s.Node.Advance(rd)
}
}
- 客户端调用RPC RawGet/RawPut/RawDelete/RawScan
- RPC handler 调用
RaftStorage中的相关读写方法 RaftStorage向raftstore发送Raft命令请求并等待回复RaftStore将Raft命令作为Raft日志写入PeerStorage并同步- Raft模型提交日志
- Raft worker执行Raft命令并处理Raft ready,将结果通过callback返回
RaftStorage接收到结果并返回给RPC handler- RPC handler处理得到结果返回给客户端
在执行过程中有一些错误情况,相关的error可以直接包装进RaftCmdResponse中的RaftResponseHeader中返回。具体的,可以直接使用kv/raftstore/cmd_resp.go中提供的BindErrResp。在当前需要考虑的错误有:
- ErrNotLeader:raft命令被发送到了follower上,需要告知客户端尝试其他的peers
- ErrStaleCommand:某些命令的raft日志可能并没有被提交,而且被新的日志所覆盖,但客户端可能仍在等待返回结果,所以需要告知客户端重新执行命令
测试及BUG
碰到的问题以及需要注意的地方:
- 定义结构体指针后是空的,不能直接使用!!!要用new或者&赋值
- 返回committed但还没有applied的日志的nextEnts()函数中,最后返回的Index是[l.applied - firstIndex + 1 : l.committed - firstIndex + 1],尾部索引一开始没有+1导致一直无法正确返回结果给RaftCmd而内部超时(DeBug了两天!!!)
- 无论是什么操作,包括snap,记得执行完后删除proposals
- 更新AppliedIndex在HandleRaftReady中更新就好了,在执行Entry后不要额外更新
- 对于所有节点都应该在HandleRaftReady中执行已经Committed的指令,而只有Leader节点处理proposal的回复
- 在newRaft的Config参数中,如果节点是重启的话会设置Applied参数
- Follower在处理Leader的附加日志请求时,需要注意只有在接收到的commit参数大于本地committed参数时,才更新committed参数。否则可能会因网络延迟导致committed参数的倒退,applied大于committed。(n天又没了)
- 在处理proposal时,如果proposal的term或者index与entry的对不上,需丢弃无效proposal,否则会妨碍之后proposal的处理
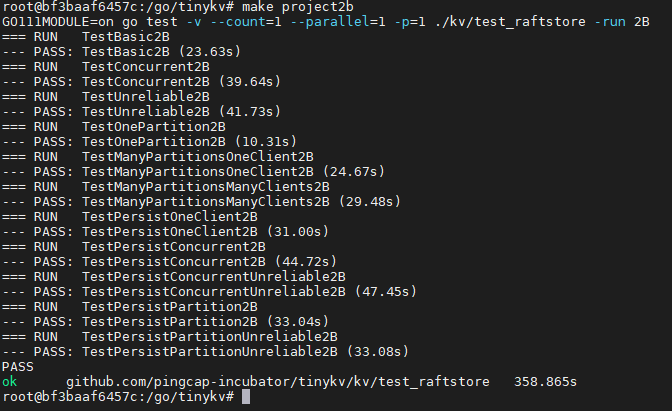
运行make project2b通过测试
Part C
在实际的存储系统中,raft日志会随时间不断增多,然而存储大量的日志信息会影响系统的存储空间和运行效率。因此,当日志长度超过一定的阈值时,系统会生成快照并丢弃无用的日志信息,实现日志的压缩。
实际上快照Snapshot和AppendEntries一样,是一个需要同步给follower的raft消息。不同的是快照的规模很大,包含了某个时间点整个状态机的数据,所以快照消息会使用独立的连接传输数据。
本地生成快照
Raftstore在每次时钟OnRaftGcLogTick()中都会检测日志的长度是否超过了设定的阈值RaftLogGcCountLimit,如果是,则会发送一个raft管理命令CompactLogRequest,被包装在RaftCmdRequest(与Get/Put/Delete/Snap相同),在经过Raft提交后,每个节点都会执行该日志压缩的命令,向 raftlog-gc 线程发送ScheduleCompactLog任务,生成快照。
1 | func (d *peerMsgHandler) processAdminRequest(entry *eraftpb.Entry, msg *raft_cmdpb.RaftCmdRequest, wb *engine_util.WriteBatch) { |
发送与接收快照
如果需要给Follower发送的日志信息已经被压缩,这时候Leader则需向Follower发送快照。Leader调用Storage.Snapshot()向region worker发送RegionTaskGen生成快照,之后再次调用该函数时会检测快照生成是否完成,如果完成就返回快照用于发送。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21func (r *Raft) sendAppend(to uint64) bool {
index := r.Prs[to].Next - 1
logTerm, err := r.RaftLog.Term(index)
if err == ErrCompacted {
snapShot, err := r.RaftLog.storage.Snapshot()
if err != nil {
return false
}
r.msgs = append(r.msgs, pb.Message{
MsgType: pb.MessageType_MsgSnapshot,
From: r.id,
To: to,
Term: r.Term,
Snapshot: &snapShot,
})
r.Prs[to].Next = snapShot.Metadata.Index + 1
return false
}
...
}onRaftMsg中进行具体的快照接收,然后调用handleSnapshot来处理消息,修改term、commit index和集群成员等信息。
1 | func (r *Raft) handleSnapshot(m pb.Message) { |
修改的信息会被反应到Ready中来处理,在ApplySnapshot中,向region worker发送runner.RegionTaskApply应用快照,并更新RaftLocalState. RaftApplyState, RegionLocalState等状态,持久化写入kvdb和raftdb中。
1 | // Apply the peer with given snapshot |
测试和BUG
一些出现的问题和BUG:
- 在处理CompactLog命令时,判断CompactIndex和TruncatedState.Index的大小
- 在handleSnapshot()中,需要将r.Raftlog.entries清空
- 在RaftLog.Term()中,需要判断是否在接收快照而做额外的处理
- 需要考虑在接收Snapshot前来了AppendEntries消息,FirstIndex为快照index + 1
- RaftLog中firstIndex的获取不能直接调用storage.FirstIndex()(返回truncatedIndex + 1),在RaftLog.entries没有被压缩不为空的情况下应直接返回RaftLog.entries[0].Index。(其实最好的办法是在RaftLog中加入成员变量FirstIndex,失策)
make project2c通过测试